
决策树分类算法研究

决策树分类算法研究
附加基于人工智能的决策树分类算法研究
一、实验目的
决策树归纳是最简单但最成功的学习算法之一。决策树(DT)由内部和外部节点以及组成节点之间的互连称为树的分支。内部节点是一个决策单元根据不同决定下一个要访问的子节点相关变量的可能值。相比之下,外部节点也称为树叶节点,是分支的终止节点。它没有任何子节点并且是与用来描述给定数据的类标签相关联。决策树是树中的一组规则结构,其中的每个分支都可以被解释为沿着这个分支访问的节点与之相关的决策规则。
决策树通过从树根到树叶节点对树进行排序来对实例进行分类。这个树形结构的分类器将数据集的输入空间递归分割互相排斥的空间。按照这种结构,每个训练数据被标识为属于某个子空间,它被分配了一个标签,一个值或一个动作表征其数据点。决策树机制具有良好的透明度我们可以很容易地遵循树状结构来解释如何做出决定。因此,当我们澄清有条件的规则特征时,可解释性就会增强。
随机变量的熵通过生成的平均信息量观察它的价值。考虑用硬币掷硬币的随机实验正面的概率等于0.9,因此P(Head)= 0.9,P(Tail)= 0.1。这可提供比P(Head)= 0.5和P(Tail)= 0.5的情况更多的信息。
熵通常用于评估物理学中的随机性,其中熵值较大表明该过程非常随机。决策树是根据每个属性的信息内容进行启发式指导的。熵作为分类的手段用于评估每个属性的信息。
我们也可以说熵是一个样本集合中的杂质度:熵越大,数据越不纯。基于熵,信息增益(IG)通常被用于衡量类间区分的有效性。
二、决策树分类算法实现
2.1模型构建
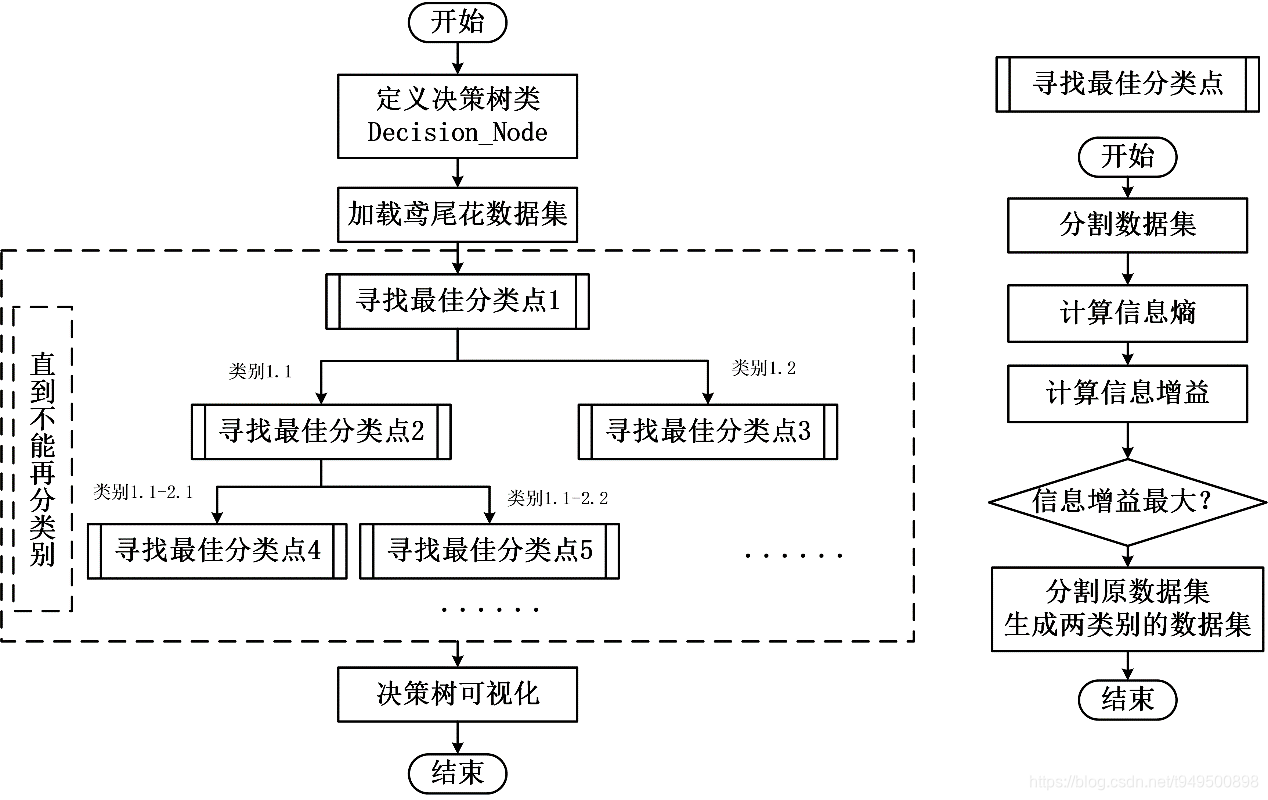
- 定义决策树的类。其中包含分类特征,分类界值,第一类,第二类,第一类的熵,第二类的熵。每进行一次分类后,均保存为这样一个数据结构;
- 加载鸢尾花数据集。数据集包含5列,前四列分别是分类的特征:“花萼长度”, “花萼宽度”, “花瓣长度”, “花瓣宽度”,最后一列是样本的标签,即该一行的鸢尾花属于什么类别,此处共有3个类别;
- 构建决策树。主要是利用递归的思想,先找到第一层的最佳分类点,即找到最佳分类属性与分类值,分割数据集后再继续进行下一层的最佳分类点搜寻,直到划分后的数据不能再划分为止。其中,寻找最佳分类点子过程为,对每一个属性,每一个值当做分类点,计算此时的信息熵与信息增益,找到信息增益最大的分类属性与分类值,再划分数据集,保存构建的决策树类。
2.2决策树的可视化
2.3结果分析
程序运行结果:输出决策树每一次分类的分类属性以及分类值,每一次分类之后的熵,到不能再分类时该类的类别以及该类别的数量。
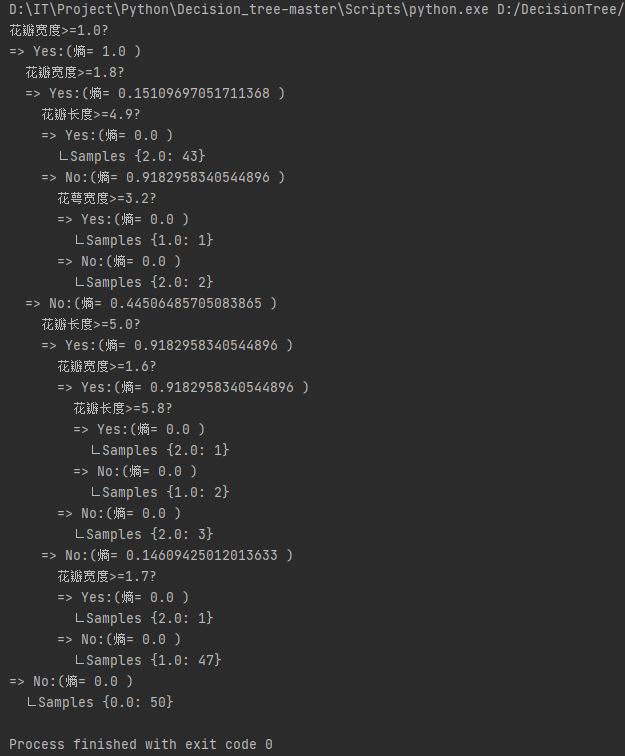
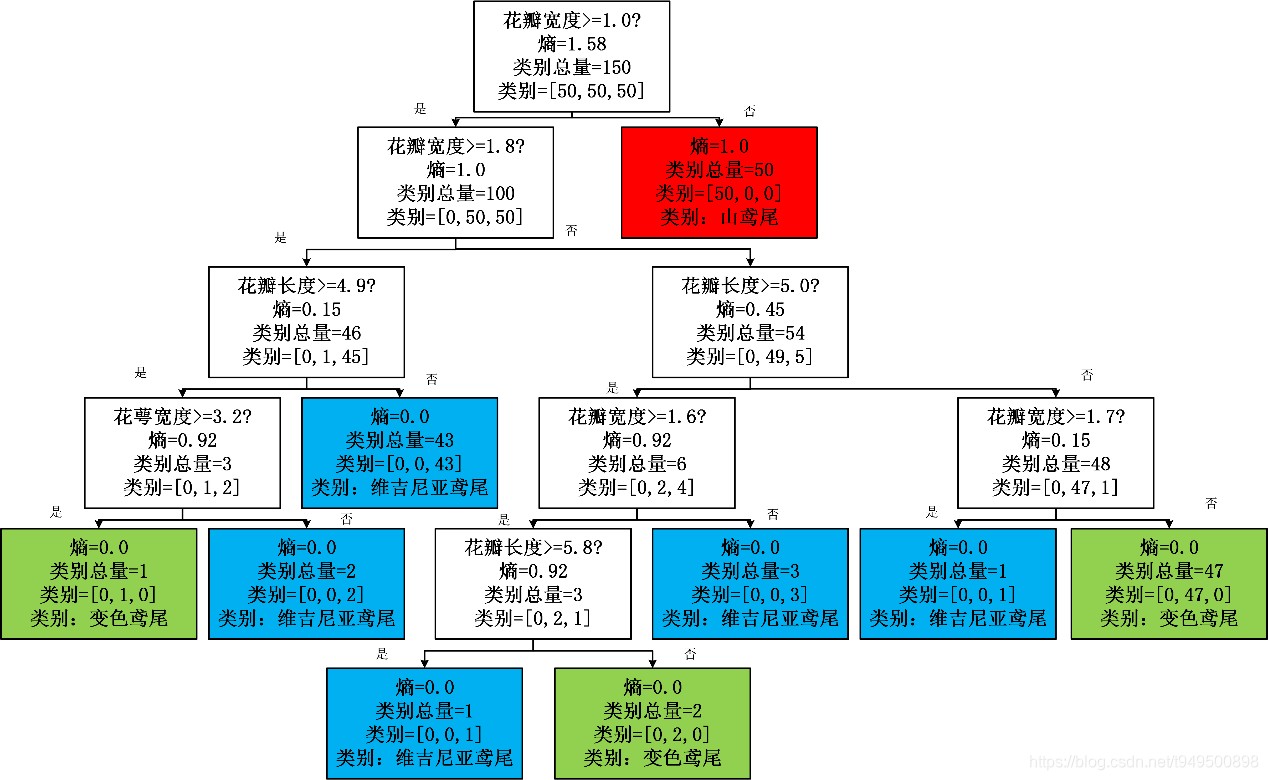
根据输出结果,画出树状的分类结果图如图3,分类到最后三种类别,分别用三种颜色来表示,(山鸢尾:红色;变色鸢尾:绿色;维吉尼亚鸢尾:蓝色)可以看到,在第一次分类时,即通过花瓣宽度将第一类山鸢尾分出来,后面最多5次分类即可将三种类别全部分割出来。
三、对比综合实验
为了更好地对比实验,选用经典二分类问题,即选择scikit-learn中breast_cancer(乳腺癌)数据集进行实验分析。
数据描述:该分类数据集包含569条数据,30个属性,均为连续属性,目标是对该数据集进行二分类问题,即判断属于’malignant’(恶性), ‘benign’(良性)中的哪一类。
本程序将569份数据按照7:3比例进行划分,其中400份数据作为训练集,169份数据作为测试集。
3.1决策树深度对模型精度影响
为了探索决策树的大小和模型准确率之间的影响和联系,方便起见,调用sklearn中的决策树分类工具包(DecisionTreeClassifier),设置决策树最深深度这一参数(max_depth)分别为4,5,6,7,8进行实验,在训练集上(400份数据)训练,在测试集(169份数据)进行测试。同时记录训练模型所用的时间,输出最终生成树的大小,输出模型的准确率,并且输出分类模型的评价(包含precision, recall, f1-score, support),输出模型的混淆矩阵。
在测试完上述四个参数后,汇总结果,输出决策树的平均耗时,并且输出最优决策树模型(以准确率作为评判标准),最大深度,以及相应的准确率,最终,得到结果如下图所示:
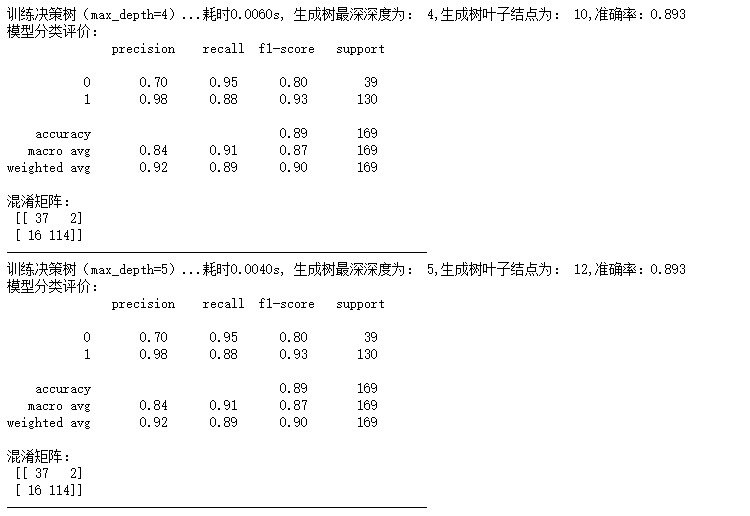
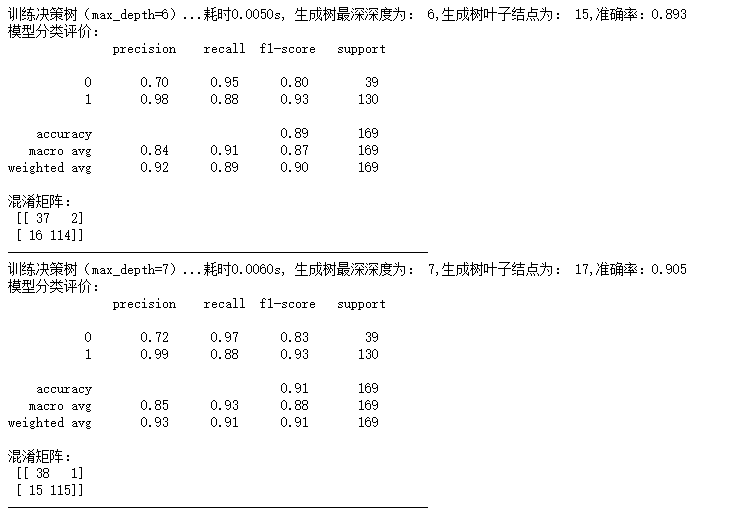
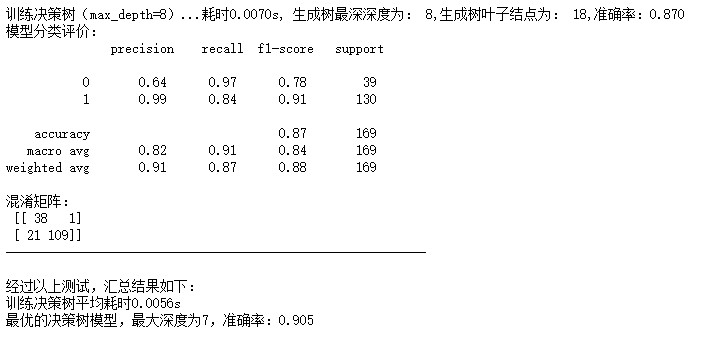
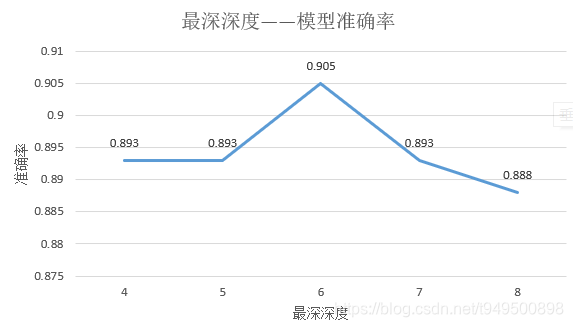
由以上输出结果表明,决策树最大深度为6时,准确率为0.905,此时,训练决策树共耗时0.006s,决策树叶子结点为15,相应的f1-score等评价指标也较高,此时模型结果达到最优。
由于本数据集数据量较小,训练较快,训练的耗时均比较小,没有比较的意义;另外,随着最深深度的增加,模型的叶子结点数量也在增加,决策树变得更加庞大和细致,但是,在测试集上的表现并没有随着决策树增大而效果变好,可能是出现了对训练集过拟合的情况,因此,在选择决策树最深深度时,需要根据实际情况,选择适当的深度。
3.2决策树特征选择标准对模型精度影响
同上述探究决策树大小对模型精度影响的研究方法,对参数特征选择标准criterion进行设置,可以使用”gini”或者”entropy”,前者代表基尼系数,后者代表信息增益。默认使用的是基尼系数”gini”,即CART算法,但最基础的决策树分类算法是基于ID3, C4.5的最优特征选择方法,无论哪种方式是都可以适用于本数据集类型的连续变量。进行选择后,输出结果如下:

通过分析,选择信息增益为特征选择标准,在小数据集上效果较好,而大数据集上,虽然在对训练样本集的学习中可以尽可能多地挖掘信息,但其生成的决策树分支较大,规模较大,为了简化决策树的规模,提高生成决策树的效率,就出现了根据GINI系数来选择测试属性的决策树算法CART。由于本数据集数据量不大,仅有400个作为训练样本,因此相对来说,选用信息增益为特征选择标准对模型表现结果较好。
3.3决策树叶子结点最小样本数对模型精度的影响
探究决策树叶子结点最小样本数对模型精度影响,本质上是在探究“剪枝”策略对决策树的影响,沿用上述两种对比试验的研究方法,对参数特征叶子结点最小样本数min_samples_leaf进行设置,在这里设置参数分别为1,2,3,4,5,输出结果如下:
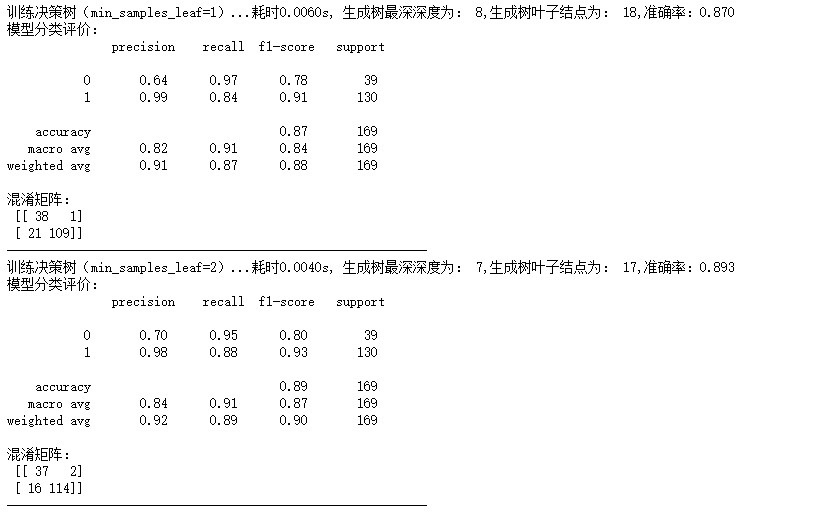
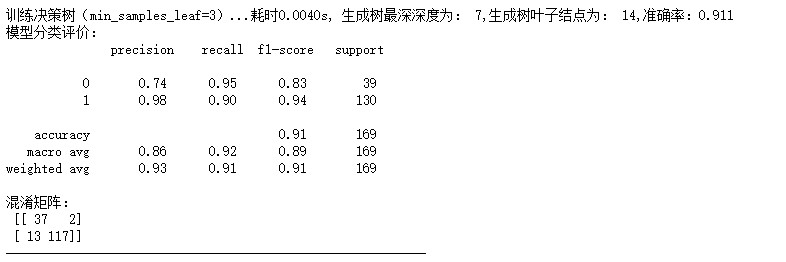
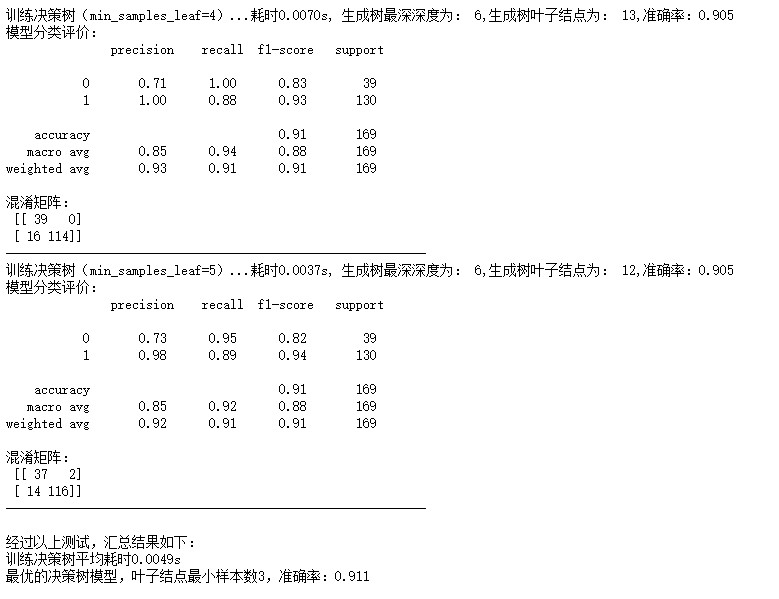
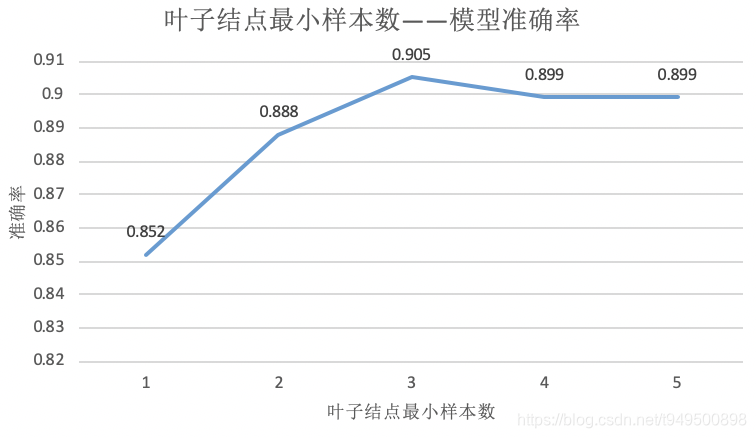
由以上输出结果表明,决策树叶子结点最小样本数为3时,准确率为0.905,此时,训练决策树共耗时0.005s,决策树叶子结点为14,相应的f1-score等评价指标也较高,此时模型结果达到最优。
由实验结果可知,决策树叶子结点最小样本数越大,一般情况下决策树分支会减小,决策树整体变小,有一定的抵抗对训练数据过拟合的能力,但随着叶子结点最小样本数大到一定程度,模型的准确性又会难以保证,本次实验得到当叶子结点最小样本数为3的时候,模型准确度最高,因此,在选择决策树叶子结点最小样本数时,需要根据实际情况,选择适当的值,即通过“剪枝”的思想,控制决策树的大小,提升模型对于测试集的精度。
3.4最优决策树相关分析
通过上述的各个参数的调整与研究,总结测试,得出结论,在本项目中,选用决策树的参数为criterion=‘entropy’,max_depth=15,min_samples_leaf=3,输出结果如下:
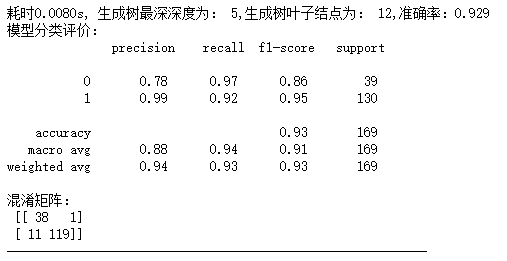
由以上输出结果表明,此时模型的准确率达到0.935达到最高,此时,训练决策树共耗时0.0132s,决策树深度为5,叶子结点为12,相应的f1-score等评价指标也较高,此时模型结果达到最优。
接下来,调用graphviz和pydotplus工具包,设置好参数路径,可视化决策树:
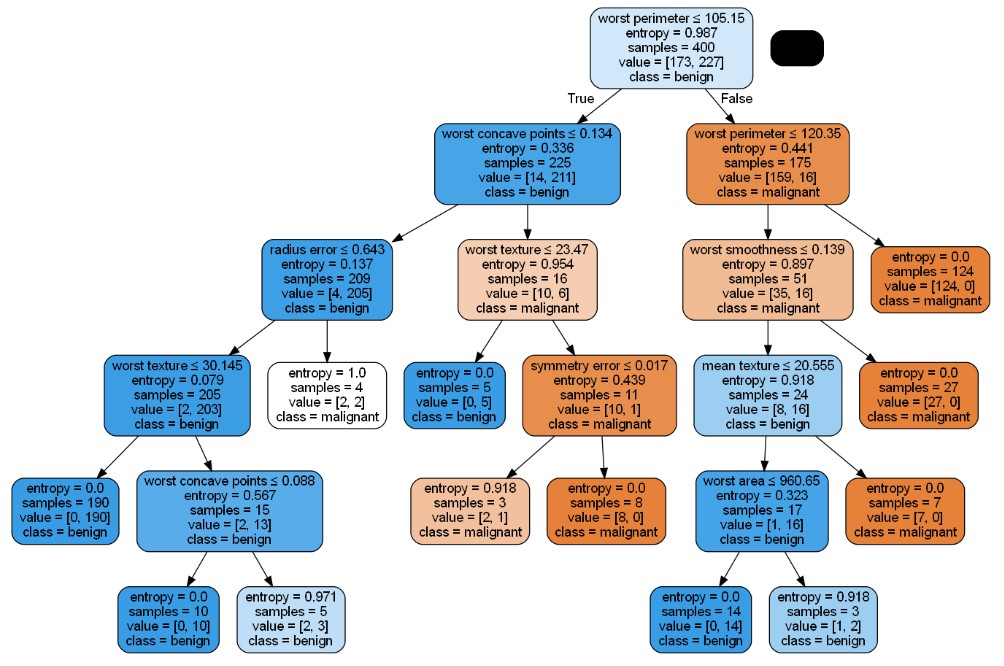
蓝色代表分类为正常’benign’,橙色代表分类为患病’malignant’,颜色越深表示此类样本中只含有这一类,越浅表示分类界限不明确。综上,决策树可以较好地完成该二分类问题。
接下来,为了观察决策树的分类效果,根据决策树的分类过程对采用的30个特征做重要度排序:
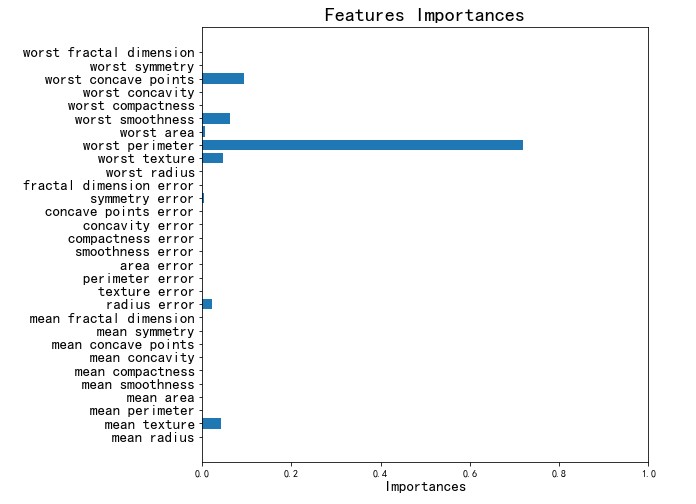
可以看到’worst perimeter’和’wort concave points’这两个特征的重要度最高,以这两个特征分别为横轴和纵轴,绘制样本的散点图,并且根据排序结果进行分类,有以下结果:
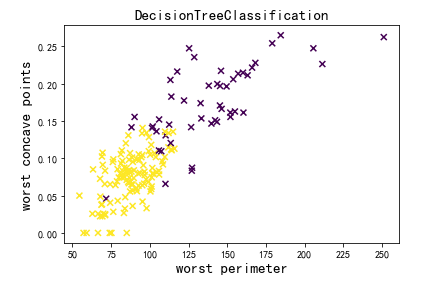
由上图,可以看到黄颜色的样本和紫颜色的样本成功被分为两类,分类界限也比较明显,决策树分类效果比较好。
3.5贝叶斯网络分类
为了对比贝叶斯网络与决策树分类的结果,基于相同的scikit-learn中breast_cancer(乳腺癌)数据集,调用sklearn.naive_bayes中的GaussianNB分类模型进行实验,有以下输出结果:
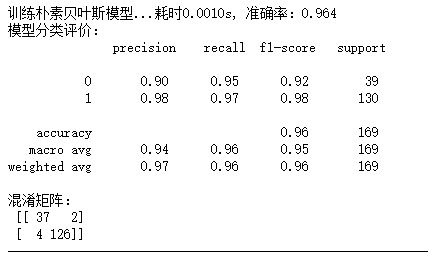
由上述输出结果可以看到准确率达到了0.964,没有参数的调整,效果优于决策树分类的最佳结果0.935。说明在该问题中,样本数量不是很庞大,贝叶斯网络效果更佳,另外,由于人口中不会大量发生癌症,样本的不均衡性,也导致决策树算法的分类性能降低。综上所述,在本项目中适合采用朴素贝叶斯网络进行分类。
3.6对比综合实验结论
与朴素贝叶斯分类相比,决策树学习的优点和缺点。
最优决策树的相关分析,贝叶斯网络的分类结果可以看到,针对同样的数据集,两种方法均能够较好地完成该二分类的任务,但是就具体问题而言,贝叶斯网络的效果更好,原因可能是因为数据样本比较少,样本不均衡等原因。通过实验体会和查阅资料,总结:
决策树的优点:
- 决策树易于理解和解释;
- 能够同时处理数据型和常规型属性;
- 在相对短的时间内能够对大型数据源做出可行且效果良好的结果;
- 比较适合处理有缺失属性的样本;
- 能够处理不相关的特征;
决策树的缺点:
- 对于那些各类别样本数量不一致的数据,在决策树中,进行属性划分时,不同的判定准则会带来不同的属性选择倾向;
- 决策树处理缺失数据时的困难;
- 过度拟合问题的出现;
- 忽略数据集中属性之间的相关性。
四、总结
通过此次决策树的学习和代码的运行,我掌握了决策树基础算法的逻辑,和如何解析数据使得数据符合决策树算法输入。决策树的算法不需要调整过多的参数,同时算法的可解释性也非常简单直观。但决策树的缺点也同样在此次实验中暴露出来了,当决策属性过多,整个决策树的算法的开销将会膨胀到非常大。同时这样扩展出来的数据集也容易达到过拟合的状态。于是学者之后还研发出来了预剪枝,和后剪枝等技术,以及使用随机森林算法来解决这些相关问题。


















