
基于循环神经网络的对联自动生成研究

基于循环神经网络的对联自动生成研究
附加基于循环神经网络的对联自动生成研究
一、概述
1.1 选题背景及意义
深度学习的概念最早由 Geoffrey Hinton 在 2006 年提出,其兴起于图像识别领域,在之后的很短时间内,深度学习技术广泛应用于机器学习的各个领域。在AI领域中,自然语言处理(Natural Language Processing,NLP)是一个占据着极其重要地位的子领域,它的发展可以使计算机理解和利用人类语言,使计算机达到认知智能,并逐步迈入感知智能[1]。NLP主要包括语言理解和语言生成两大部分。在语言生成范畴,诗歌和对联的自动生成是一个非常重要的分支,具有很强的前瞻性,一直是学术界研究的热点。
在本文中,我们研究了对联的自动生成。我们提出了一个基于注意力的编码器-解码器模型来接收前从句,并在对联对中输出后续子句。给定任何指定的先行从句,我们学习单个字符的表示,以及从句中的组合,以及它们如何相互加强和约束。我们可以使用编码器解码器模型生成后续子句。在生成过程中,我们结合了注意力机制,以满足对联的特殊性。
使用深度神经网络进行对联的生成研究是一项十分具有意义的工作,对联的自动生成,也是对自然语言处理领域中一个具体方面的深入探索和研究,对自然语言处理领域内的其他任务也有一定的借鉴参考价值;使用机器学习方法进行对联的创作,可以将其生成方法拓宽到其他场景下,促进中国传统文化的传播和发展。
1.2 开发团队
组员:
富佳、夏取明、王艺凡
具体分工:
富佳:组长;数据集整理,预处理;展示界面搭建;报告撰写
夏取明:模型搭建训练及模型预测; 参考文献收集
王艺凡:数据集搜集;参考文献收集;报告撰写
1.3 开发环境
| 操作系统 | Windows |
|---|---|
| CPU型号 | AMD Ryzen 5 4600U with Radeon Graphics |
| GPU型号 | AMD Radeon(TM) Graphics |
| 内存 | 16.0 GB |
| 主要工具 | Anaconda、Python3.6、paddle |
1.4 国内外研究现状
在以往的研究中很少有研究关注深度学习对中国对联的应用,但有类似的文本分类识别应用在机器翻译和欧美古典诗歌自动生成等方面。机器翻译的概念始于 1949 年,1954 年美国 Georgetown-IBM 实验室第一次完成英语和俄语间的机器翻译实验,证明了机器翻译的可行性。但是在后面一段时间内,由于速度慢、消耗计算资源高、准确性低等缺点,机器翻译的发展一度停滞。直到 20 世纪 80 年代,随着社会信息服务需求的扩大,机器翻译技术在处理大量文本翻译任务的优势逐渐凸显,机器翻译的研究开始复苏。
古典诗歌自动生成的研究始于 1959 年,当时 Theo Lutz 通过计算机创作了第一首德语诗歌。从那时起,机器自动生成诗歌从简单的词堆栈方法开始,然后逐渐发展到现在的基于案例的推理方法以及其他新兴的方法,可分为基于模板的生成方法、基于遗传算法的方法、生成和测试方法以及基于案例的推理方法。很少有研究关注中国对联的产生。中国对联生成任务可以看作是两句诗生成的简化形式。给定诗的第一行,生成器应该相应地生成第二行,这与对联生成的过程类似。但是,对联生成和诗歌生成之间仍然存在一些差异。生成后续从句以匹配给定的前置从句的任务比生成一首诗的所有句子更明确。此外,并不是诗中所有的句子都需要遵循对联的约束。
总的来说,国内基于seq2seq的对联自动生成系统在技术上已经取得了一定的进展,但仍面临着诸多挑战,如语义理解、语法结构、韵律要求等。未来,随着深度学习技术的不断发展和对联生成应用场景的不断拓展,这些挑战将逐渐得到解决,对联生成系统的性能和应用前景也将不断提升。
二、相关理论及其技术介绍
2.1 循环神经网络
2.1.1 标准循环神经网络
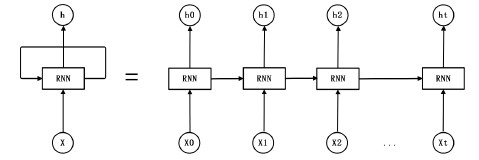
基础的神经网络包括输入层、隐藏层和输出层三层结构,其只在层与层之间建立连接。而标准循环神经网络 RNN(Recurrent Neural Network)在此基础上,在同层之间的神经元之间也建立了连接。RNN 的神经网络结构如图 2.1 所示,等号右边为神经网络按时间展开图,等号左边是其简化图。
2.1.2 长短时记忆网络
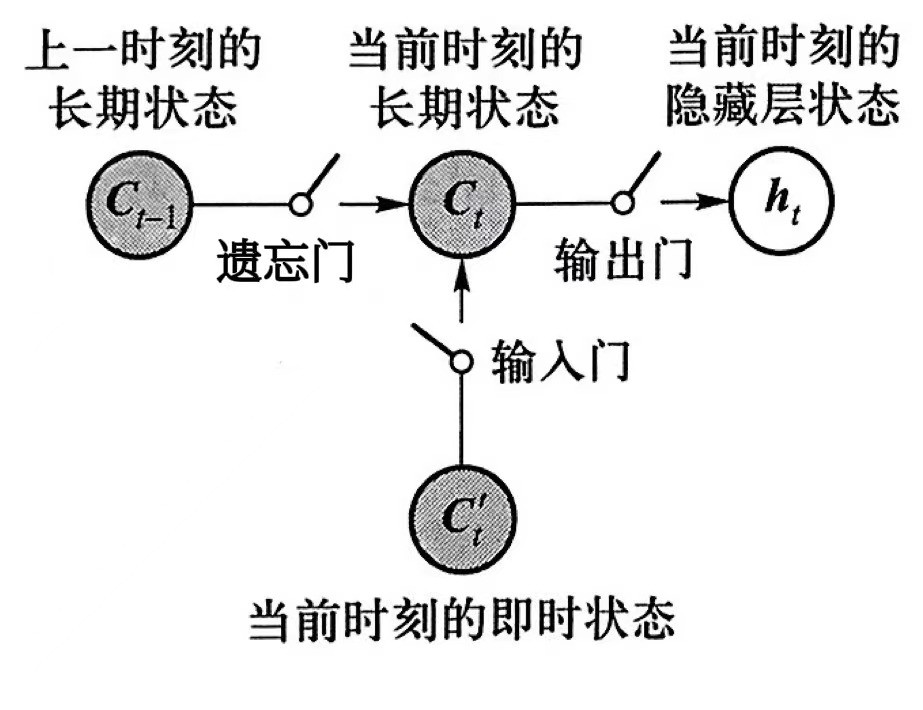
长短时记忆网络 LSTM 是循环神经网络的一个最常见的扩展模型,其就是为了解决一般 RNN 网络的缺陷,更有效的应对产期依赖问题。LSTM的隐藏层比RNN更为复杂,采用了三个“门”结构,用来解决长期依赖问题。如图2.2所示LSTM的隐藏层分别包含了输入门、遗忘门和输出门。
这是最基本的 LSTM 结构,目前有 LSTM 的变种形式如 GRU 等等,但是基本思想都是统一的。LSTM 和 GRU 是目前比较常见的神经网络隐藏层单元结构,除此以外,还有 Koutnik提出的 Clockwork RNN 结构,Yao 提出的 Depth Gated RNN 结构等[2],对于具体的任务,可以适当变形以适应任务需要。
2.2 注意力机制
注意力机制(Attention Mechanism,简称 AM)最早的提出是在图像领域,受到人类注意力机制的启发,人类观察图像时往往有重点的将注意力集中在图像的特定部分并且会根据之前观察图像的经验来观察之后的图像。基于注意力机制的文本分类机制为每个词赋予了权重α,并根据权重生成语义编码C。其编码的三个阶段具体计算步骤为:
- 计算 Query和不同 Key 的相关性,计算不同 Value 值的权重系数。
- 对上一阶段的输出进行归一化处理,将数值的范围映射到 0 和 1 之间。
- 根据权重系数对Value进行加权求和,从而得到最终的注意力数值。
在注意力模型中,由于每一次输出的词语在计算的时候,使用到的语义编码C 都是不一样的,这也体现出注意力的意义,在很多任务中都已经取得了很好的效果。
2.3 序列到序列模型
2.3.1 经典的序列到序列模型
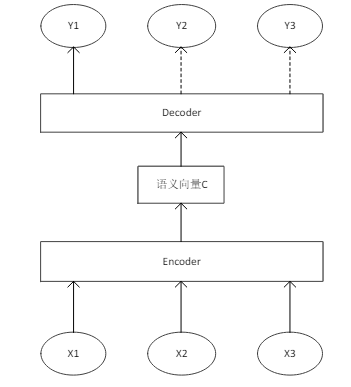
序列到序列模型(seq2seq)亦称为编码-解码模型,由谷歌公司于2014年在论文《Sequence to sequence learning with neural networks》中提出。序列到序列模型的提出在整个深度学习领域获得了很大的影响。近年来在机器翻译、语音识别、图像识别、文本生成等领域的大部分研究都是围绕序列到序列的模型框架展开。如图2.3所展示了一个经典的序列到序列模型。模型包含了一个编码器(Encoder)和一个解码器(Decoder),编码器的作用是提取输入序列特征,并将其压缩成一个固定大小的语义向量C,解码器的作用是解读语义向量C,将其转化为目标输出序列。其中编码器和解码器一般采用循环神经网络[3]。
2.3.2 基于注意力机制的序列到序列模型
经典的序列到序列模型在很多问题上都非常有效,但是也存在问题。最大的不足在于,编码器和解码器仅通过一个固定的语义向量C进行联系,每个输出时刻语义向量的值都是不变的,且语义向量并不能够将整个序列的信息完全表示,如此解码器在每个时刻仅根据历史的信息和固定的语义向量C进行输出,这样会导致本应该和输出强相关的输入信息被严重的稀释了[4]。
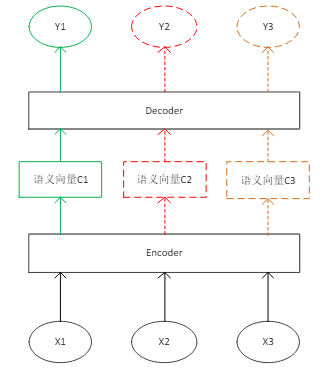
因此将注意力机制应用于序列到序列模型,如图2.4展示了基于注意力机制的序列到序列模型示意图。用经典的序列到序列模型结合注意力机制,使得编码器和解码器之间通过一个可变的语义向量进行联系,每个输出时刻语义向量都是不同的,可变的Ci表示了每个时刻输出最相关的输入信息。
本文主要用到基于注意力机制的序列到序列模型,因此这里展开描述基于注意力机制的序列到序列模型计算过程步骤:
假设基于注意力机制的序列到序列模型输入的源序列为S = (x1,x2,…,xm),输出的目标序列为T= (y1,y2,…,yn),那么在第i时刻模型的输出计算过程可以表示如下:
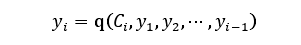
其中,Ci不是一个固定的值,会根据每一个时刻的变化而变化,由编码器的隐藏向量(h1,…,hm)通过如下公式计算得到:
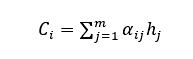
其中,𝛼i𝑗为注意力权值,计算公式如下:
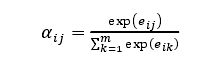
其中,
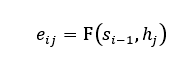
其中,𝑠i−1表示解码器第i-1时刻的隐藏层状态,函数F(𝑎, 𝑏)表示计算a和b的相似度。首先计算解码器隐藏层状态和编码器隐藏层状态的相似度,然后对计算出的相似度采用类Softmax函数进行归一化,得到注意力权值,最后注意力权值与编码器隐藏状态相乘求和得到语义向量Ct。
三、对联生成模型设计
3.1 Encoder-Decoder 框架结构简介
对联生成问题为典型的序列生成问题,这里采用最经典的 Encoder-Decoder框架结构,由于预测句子中下一个词一般需要用到前面已经生成的词,前后词语之间并不是独立的,RNN 同层节点之间相互连接能够体现这种前后词语之间的联系,并且同层节点之间的权值是共享的,因此本文任务选择使用 RNN Encoder-Decoder。一般的 RNN 结构需要将输入压缩成一个固定长度的向量,这就很难处理一些比较长的句子,特别是那些比训练集中语句更长的语句,本文在编码阶段采用的是双向RNN结构——BiGRU,这在语音识别方面已经得到了很有效的应用,解码阶段选择的就是GRU 结构。为了在每次生成输出词语的时候充分利用输入序列携带的信息,使输入序列中的不同词语对输出词语有不同的影响,本文在解码阶段使用了注意力机制。另外,为了体现上下联语句在语义和语境上的一致性,本文在解码的时候将含有上联整句信息的句向量考虑进去,下图是本文建立的对联生成模型的总体结构图。
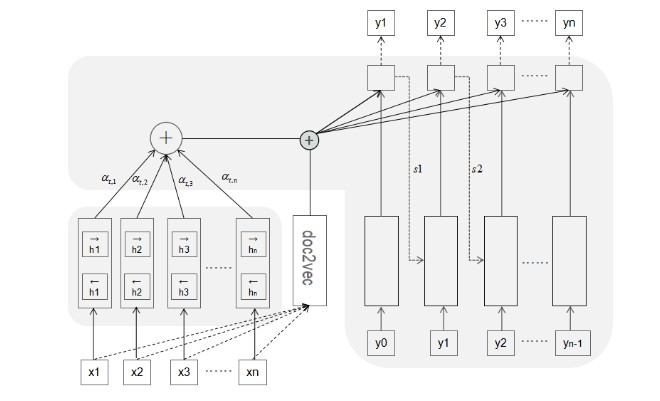
3.1.1 输入处理
本文任务的基本模式就是,输入上联输出对应的下联,这里的输入上联是汉字组成的序列。很显然,将这个任务转化为深度学习问题,必须将上联的文字符号化输入计算机中。第一步任务就是将序列中汉字转化为一个向量,就是所谓的词向量。一般的词向量在训练时只考虑到词语与其所在训练序列中的前后词语之间的关系,由于对联任务的特殊性,不仅需要考虑前后词语之间的关系,还需要考虑上下联中对应位置的词语之间的联系,于是,在训练词向量的时候将上下联对应位置的字考虑在内,也就是将其加入上下文中,将训练出来的这种词向量称之为对联字向量。
3.1.2 编码阶段
为了体现序列前后词语之间的联系,在编码阶段本文使用的是BiGRU 的结构。门控循环单元神经网络(gated recurrent unit neural network,简称 GRU)是由 Cho 等人在 2014 年提出来的,是 RNN 的衍生物,属于 RNN 的一种变种,与 RNN 的结构本质上并没有什么不同,差异在于计算隐藏层状态的函数。
GRU 使用了更新门(update gate)与重置门(reset gate)来控制标准 RNN 的梯度消失的问题,这两个门控向量基本上决定了 GRU 最终输出哪些信息。这两门控机制能够保存长期序列中的信息,且不会随着时间变长而被清除或因与预测不相关而被移除。
本文中编码阶段使用的是双向的GRU,由图4.1可以看出,一个前向的GRU,一个反向的 GRU,正向的和反向的 GRU 实际上并没有什么区别,只是输入序列的顺序不同。
3.1.3 解码阶段
解码阶段的任务是根据输入 X 的中间语义表示 C 以及前面生成的历史信息(y1,y2,…,yi-1)来生成 i 时刻要输出的词语 yi,前面说过,解码阶段使用的依然是RNN 的变体 GRU。在基础的 Decoder 中,每个 ci 都一模一样的,并不能加强或者减轻某个字对某个词的作用大小,很明显上联中对应位置的字对当前字生成的影响较大,其他位置的字对当前字生成的影响较小。为了解决这个问题,体现出上联中不同字对于下联中不同词语的影响,在解码过程中应用了 Attention 机制[5]。AM 模型可以说是今年来 NLP 领域中的重要进展之一,其效果在很多场景得到证实。在 Decoder中加入 AM 后,在生成每一个 yi 的时候的中间语义向量 ci 都是不相同的,是根据当前生成字而不断变化的[6]。
3.2 数据处理部分
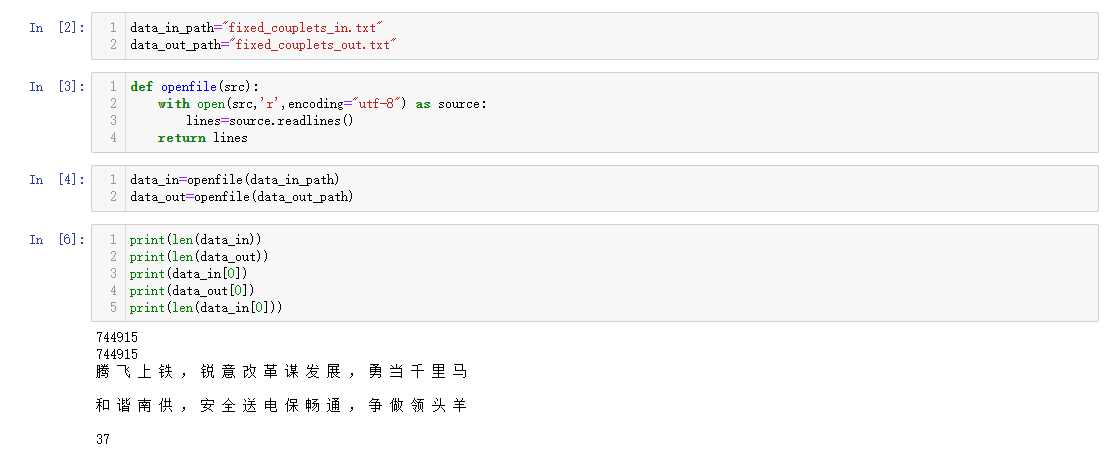
3.2.1 噪声数据摘除
数据集来源:https://github.com/wb14123/couplet-dataset 此数据集包含了五个文件,将文件按照(test+train)的顺序进行合并[7]。之后发现有14条数据有问题,其中前10个问题为上联,后4个问题为下联。经过对噪声数据进行处理后,最终获得744915条对联数据。
3.2.2 添加输入开始与结束标志
< start> 表示一个输入的开始
< end> 表示一个输入的结束

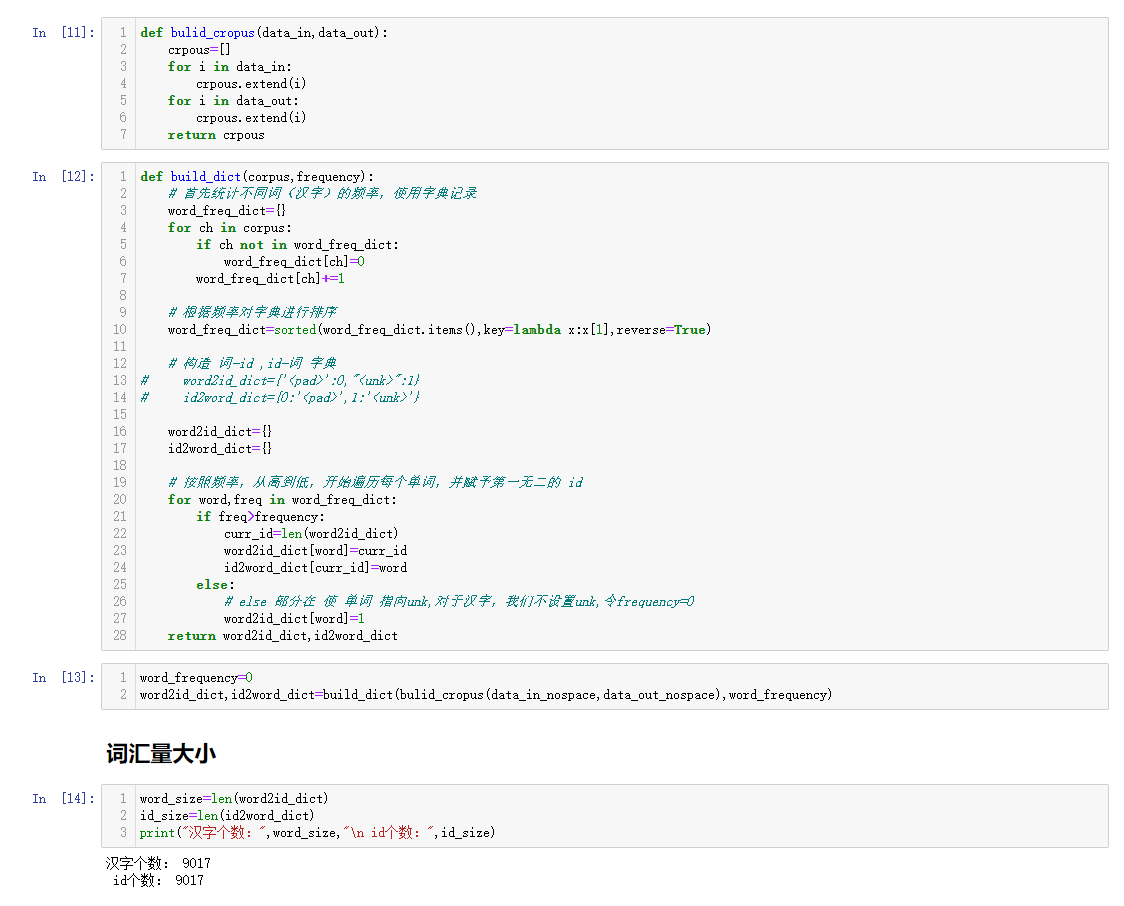
3.2.3 建立词库与字典
在字典的创建过程中,主要先用一个辅助字典,存储每个词汇出现的频率,然后根据频率排序辅助字典。然后初始化两个字典,遍历辅助字典,可用当前字典(非辅助字典)的长度作为词汇数字标识。 在该过程中,我们还可以根据频率筛选出频率大于一定阈值的词汇,即抛弃低频词汇[8]。
词库:由上下联所有字符,可用列表表示
字典:建立词汇–>向量,向量–>词汇两个字典。向量在这里可以理解为数字化,最终的目的是向量化。
3.2.4 数据向量化
根据前一步中创建的“词汇–>向量”字典将所有数据向量化。
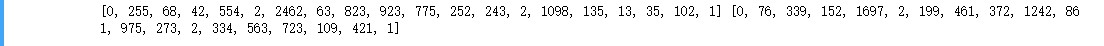
3.2.5 数据集划分及封装
我们总的数据为744915条,按照8:1:1的方式划分训练集,验证集,测试集。数据集的封装主要使用paddlepaddle以及paddlenlp提供的方法,其中paddlenlp主要是进行每个minibath数据的padding操作,统一长度[9]。
最终我们得到封装好的训练集、验证集,测试集。以训练集为例,每个元素包括五部分:
- 上联输入向量
- 输入向量未填充前的长度,用于控制LSTM的隐藏状态是否更新填充位置
- 下联输入向量,不包含最后一个位置的元素
- 下联输入向量,不包含第一个元素,然后在最后一个扩维,用于loss计算
- 下联输入向量的mask向量
四、模型训练
4.1 参数设定
- num_layers=2:LSTM的层数
- hidden_size=128:隐藏层的状态数
- embedding_dim=256:嵌入层的维度
- lr=0.001:学习率
- log_freq=200:每200个batch输入一次日志信息
- max_grad_norm=5:梯度裁剪
- optimizer=Adam():优化器,不是参数,在这里我们把他看作一个参数
- loss=CrossEntropy():损失函数,使用的是带掩码的交叉熵损失函数
- metrics=Preplexity():评价准则,困惑度
4.2 模型训练
部分关键代码:
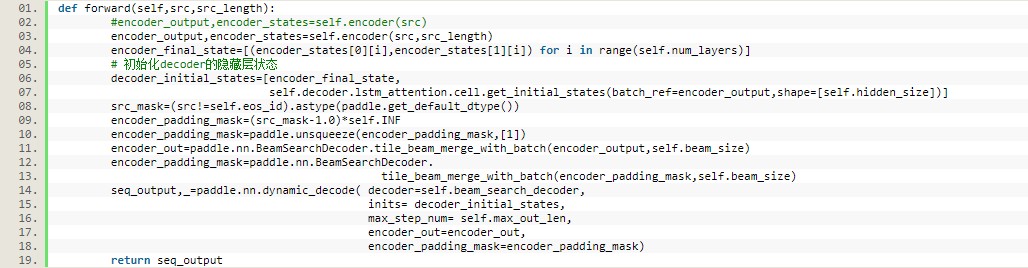
使用model.fit()函数进行训练及验证。
部分参数设置:
- epcohs=20
- eos_id=word2id_dict[‘
‘] - num_layers=2
- dropout_rate=0.2
- hidden_size=128
- embedding_dim=256
- max_grad_norm=5
- lr=0.001
- log_freq=200
4.3 模型预测
模型的预测使用了beam search(束搜索)。常规的搜索方法有greedy search(贪心搜索)和exhaustive search(穷举搜索)。
穷举搜索:穷举所有可能的输出结果。例如输出序列长度为3,候选项为4,那么就有444=64种可能,当输出序列长度为10时,就会有4**10种可能,这种幂级增长对于计算机性能的要求是极高的,耗时耗力。
贪心搜索:每次选择概率最大的候选者作为输出。搜索空间小,以局部最优解期望全局最优解,无法保证最终结果是做优的,但是效率高。
束搜索:束搜索可以看作是穷举搜索和贪心搜索的折中方案。需要设定一个beam size(束宽),当设为1时即为贪心搜索,当设为候选项的数量时即为穷举搜索。
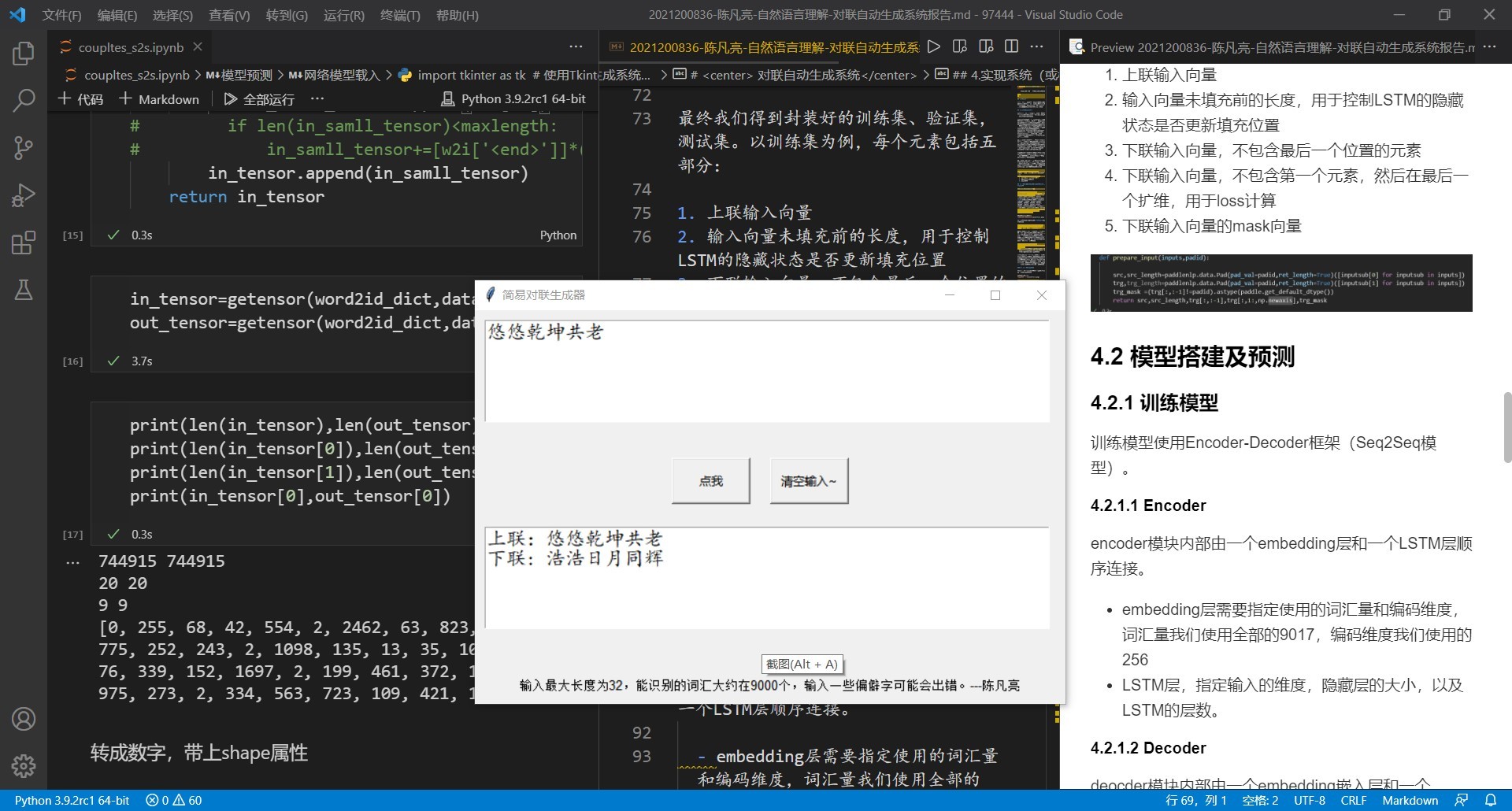
4.4 展示界面搭建
展示界面使用Python自带的TKinter包进行搭建,主要包括两个文本框和两个动作按钮。用户输入对联的上联,然后点击相应按钮,系统会提取用户的输入,将其向量化,然后送入训练好的模型中,产生输出,然后显示在另一个文本框中。
五、模型评测
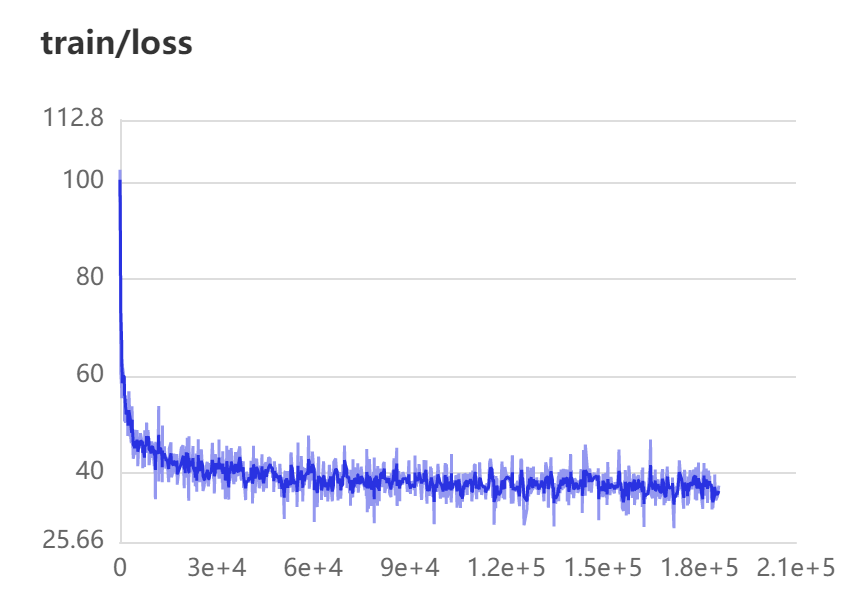
5.1 loss曲线
loss曲线数据由PaddlePaddle提供的接口在训练时保存在log文件中,之后通过可视化工具进行展示。横轴表示训练的minibatch,纵轴表示loss值。
通过训练集与验证集的lossqu曲线可以看出,训练在前期收敛较快,训练集后期有波动,但是验证集后期仍为缓慢下降趋势,说明模型的训练效果是不错的。
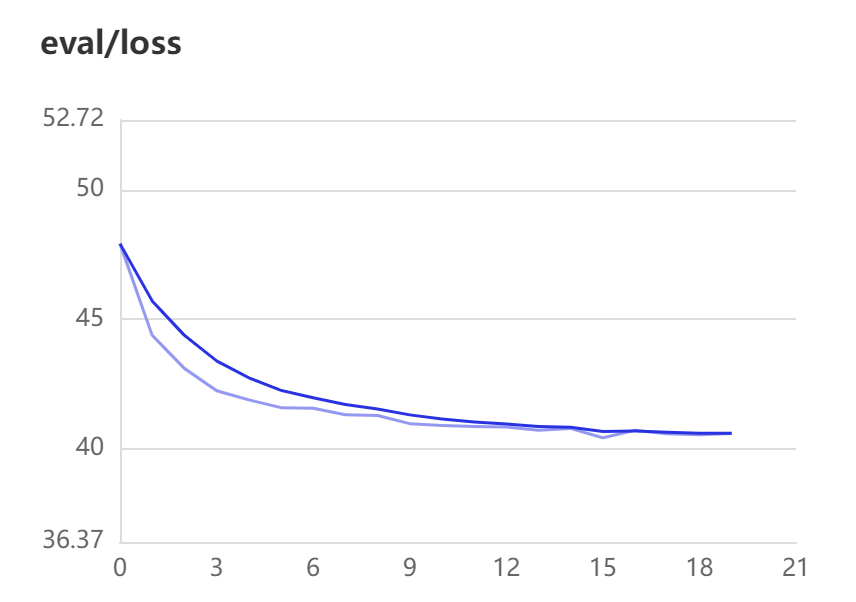
5.2 困惑度
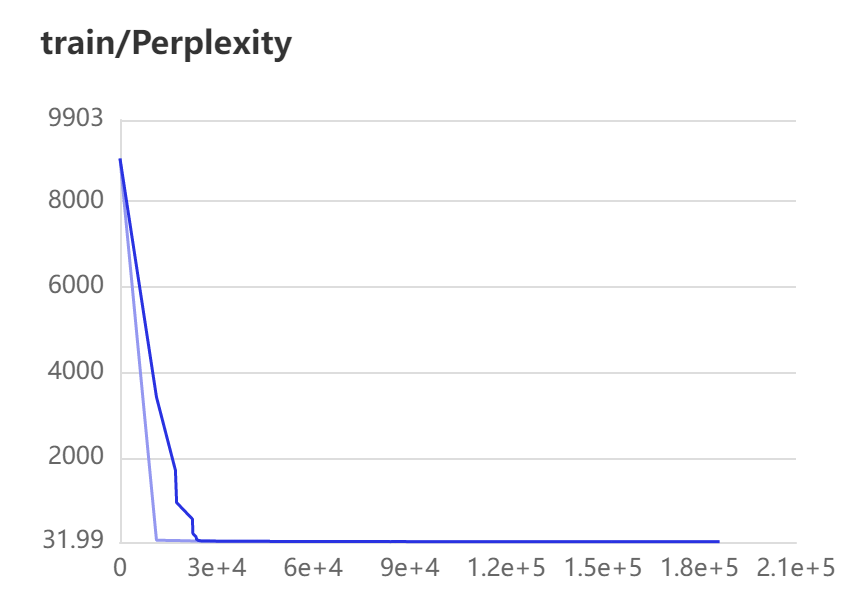
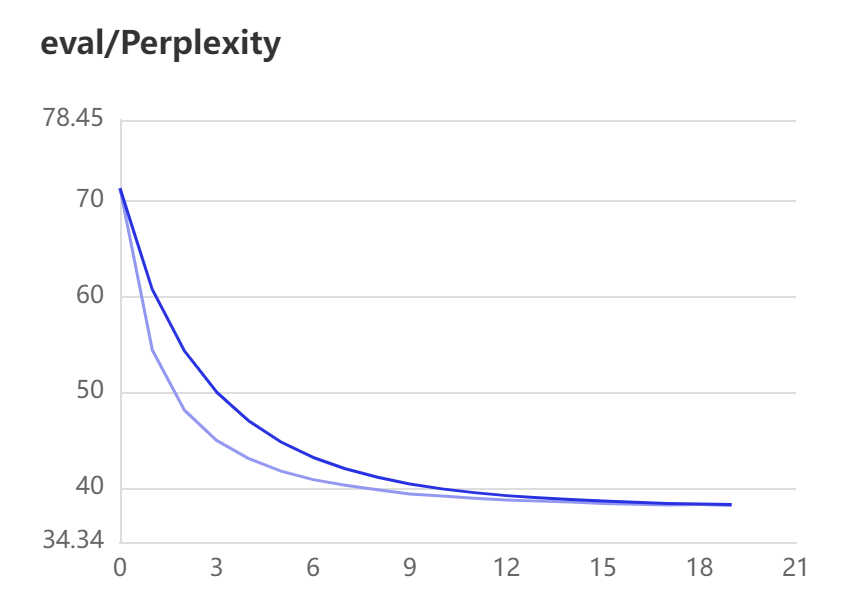
困惑度数据的获取方式同loss。通过训练集与验证集的困惑度曲线,任务模型训练效果可以。但是训练集的困惑度后期呈现为直线,这应该是存在问题的,有待分析解决。我们在测试集上进行了困惑度分析,每个batch的数据困惑度基本一致,说明模型波动较小,效果理想。
六、结语
对联是中华文化一种独特的艺术形式,其上下联之间讲究对仗工整、平仄协调,这要求对联创作者具备丰富的知识储备和深厚的文学素养,因此创作对联对普通人来说稍显困难。对于计算机来说,在自然语言处理领域,对联的生成也是一项比较困难的任务。近年来,深度学习技术快速发展,在如图像识别、语音识别等机器学习领域表现出色,自然语言处理作为机器学习的重要分支,深度学习技术也推动着自然语言处理技术不断发展。
本文首先讨论了自动生成对联的研究背景和研究意义,以及对联生成模型的国内外研究现状。介绍了循环神经网络和注意力机制,并且采用基于注意力机制的序列到序列模型对对联生成系统进行进一步研究。掌握了基于编码-解码框架的神经网络模型、注意力机制模型等算法,明确研究方向,舍弃了传统的基于循环神经网络或卷积神经网络的方法,完全使用注意力机制的神经网络结构进行对联的自动生成。结果表明注意力机制在对联的自动生成任务上具有不可替代的作用。
七、参考文献
[1] Manurung, R., Ritchie, G. and Thompson, H. (2012) Using genetic algorithms to create meaningful poetic text. J. Exp. Theor. Artif. Intel., 24, 43–64.
[2] Sundermeyer, M., Schlüter, R. and Ney, H. (2012) LSTM Neural Networks for Language Modeling. In Proceedings of Interspeech 2012, Portland, OR, 9–13 September, pp. 601–608. Association for Computational Linguistics, Stroudsburg.
[3] Papineni, K., Roukos, S., Ward, T. and Zhu, W.J. (2002) BLEU: a Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, Pennsylvania, USA, 19–24 July 2002, pp. 311–318. Association for Computational Linguistics, Stroudsburg.
[4] 王治权.基于注意力机制和改进型 RNN 的 Web 文本情感分析研究[D]. 2018.
[5] 王哲.基于深度学习技术的中国传统诗歌生成方法研究[D].中国科学技术大学,2017.
[6] Koutnik J, Greff K, Gomez F, et al. A clockwork rnn[J]. arXiv preprint arXiv:1402.3511, 2014.
[7] 蒋锐滢,崔磊,何晶,等.基于主题模型和统计机器翻译方法的中文格律诗自动生成 [J].计算机学报, 2015.
[8] Oliveira, H.G., Hervas, R., Diaz, A. and Gervas, P. (2017)Multilingual extension and evaluation of a poetry generator. Nat.Lang. Eng., 23, 929–967.
[9] Zhang J, Du J, Dai L. A GRU-based Encoder-Decoder Approach with Attention for Online Handwritten Mathematical Expression Recognition[J]. 2017.

















