
深度学习论文阅读报告

深度学习论文阅读报告
附加深度学习论文阅读报告
一、论文背景与意义
1.1论文简介
名称:基于 Bert-BiLSTM混合模型的社交媒体虚假信息识别研究
作者:冯由玲,康鑫,周金娉,李军
来源:《情报科学》期刊2024-01-29
1.2论文背景与重要性
论文背景
当今社会背景下随着互联网的深度普及和技术的不断提升,社交媒体中的真伪信息鱼龙混杂,而虚假信息一旦被接受,便很难被更正,这将对公众认知产生严重负面影响。因此,虚假信息也被世界经济论坛列为对未来社会的主要威胁研究社交媒体平台评论信息特征及真伪识别问题迫在眉睫。
论文主题
Twitter平台中疫情主题相关推文的虚假信息识别研究
论文研究的重要性
- 提高信息识别的准确性
- 加速信息处理速度
- 促进社会舆论的监控
- 推动深度学习在信息安全领域的应用
1.3论文结构
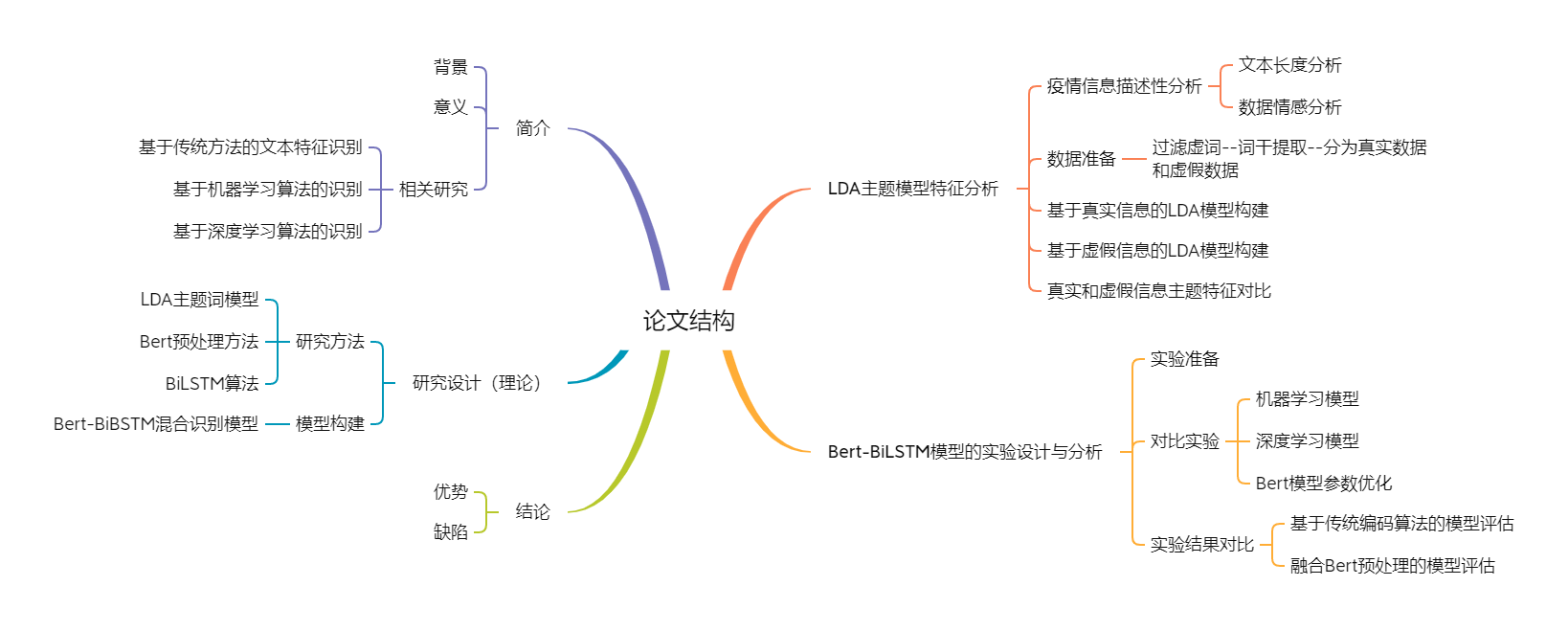
二、论文分析
2.1相关研究
虚假信息识别是一种通过构建模型的文本分类任务,通过对不同标签的文本内容进行特征提取,将文本分为虚假信息类和非虚假信息类。目前,学者们针对虚假信息识别的手段主要有三种:
- 基于传统方法的文本特征识别:费时费力,覆盖面窄。
- 基于机器学习算法的识别:对数据特征要求高,人工处理费时费力,普适性较弱。
- 基于深度学习算法的识别:Bert预训练,融合双向长短时记忆网络算法(BiLSTM),构建模型Bert-BiLSTM混合模型,识别虚假疫情信息。
2.2理论研究设计
LDA主题词模型:分析文本中隐含主题和关键信息
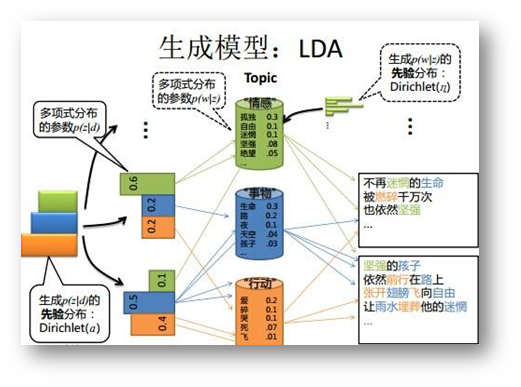
Bert预处理方法:捕捉文本间的语义关系

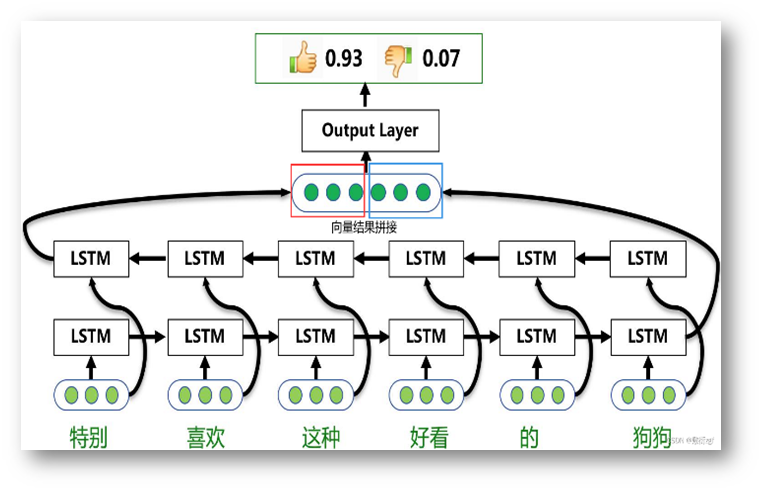
BiLSTM算法:以前向和后向两个方向处理数据,捕获序列数据中的动态时间关系
2.3LDA特征分析
文本长度分析:真实信息比虚假信息的文本长度更长
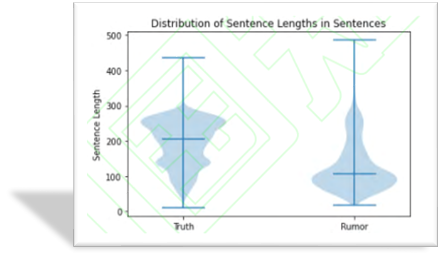
数据情感分析:虚假信息表述方式相对积极,对疫情信息的整体情感比真实信息更加乐观。 虚假信息相对真实信息情感得分较高。
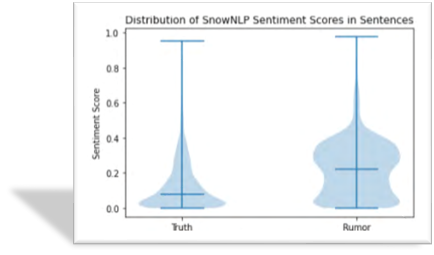
将数据使用正则表达式过滤虚词,通过NLTK对数据进行词干提取,得到归一化的文本数据,分别提取其中真实数据和虚假数据。
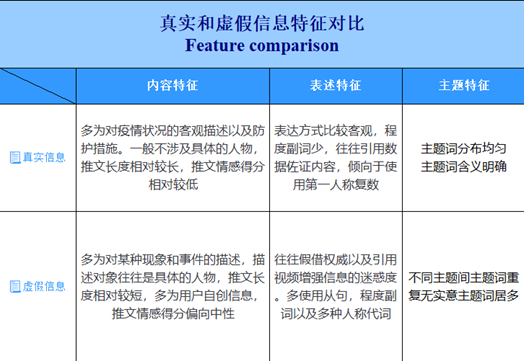
分别基于真实信息的LDA模型构建和基于虚假信息的LDA模型构建,分析出两者在内容特征、表述特征和主题特征三个维度的主要差别:
2.4Bert-BiLSTM模型实验
- 机器学习模型构建:运用 TF-IDF 和 Bert 将文本数据进行向量化处理后,分别引入到SVM(支持向量机)和RF(随机森林)。
- 深度学习模型构建:采用Keras对文本进行预处理,添加BiLSTM层(双向长短时记忆网络)和全连接层,选取激活函数Sigmoid对模型进行二分类。
- Bert模型参数优化:选取Bert作为预训练模型,参数Batch size设置为128,最大长度设置为512,并开启了最大填充以契合深度学习模型。
2.5结果分析
评价指标:准确率、精确率、召回率、F1值
准确率评估预测正确的比例;精确率评估预测正例的查准率;召回率评估真实正例的查全率;F1=(2精确率召回率)/ (精确率+召回率)
基于传统编码算法的模型评估
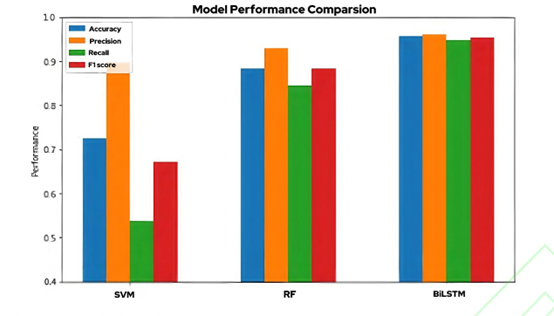
支持向量机SVM作为传统机器学习算法表现较差,集成机器学习算法随机森林RF表现较好,深度学习模型 BiLSTM 表现最佳,准确率高达 95.7%,这反映了 BiLSTM 在处理较长文本数据时识别效果更好。
融合Bert预处理的模型评估
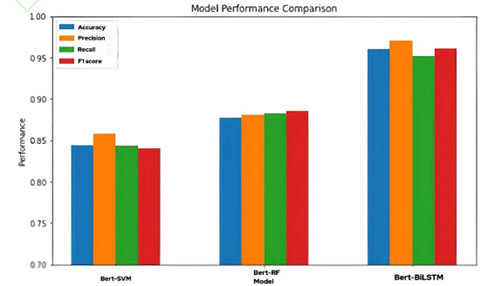
对于 Bert 预处理后的数据, BiLSTM 有最好的表现并且优于传统预处理方式下的三种模型。
总的来说,与传统预处理方式相比,Bert-BiLSTM 模型在精确率上提高了 1%。
三、见解与启示
优势
- 多主题低成本:对 Bert 模型进行了迁移构建了混合模型,相对于现有虚假疫情信息识别方法,该模型能对多主题英文文本进行低成本有效识别。
- 鲁棒性好:模型的健壮性较好,可以扩展到其他领域复杂主题虚假信息的研究中。
- 小规模数据集:运用 LDA 主题模型探究了疫情信息的特征,在小规模数据集上以较低成本实现了多主题数据的有效识别,为信息疫情治理提供了高效的解决方案。
- 对比试验:通过多方面对比使用,可靠性和真实性较高。
缺陷
- 数据集问题:当前使用的数据集长度较短,导致Bert模型需填充过多无效数据,影响性能。建议未来研究使用更长的文本数据。
- 仅限英文平台:中文社交媒体平台的虚假疫情信息数据量过小,本文仅针对英文社交媒体平台数据进行了分析。
- 算法测试限制:由于实验条件和数据限制,论文只测试了几种基本的机器学习模型。未来研究可以探索更多适合的算法,以优化虚假信息的识别效果。
- 数据忽略表情元素:在基于LDA进行疫情信息特征分析时,通过正则表达式清洗掉原始数据中的大量链接锚和表情符号,得到本文的初始数据。清洗掉表情符号会对结果造成一定影响,现代社会表情符号在语句中的作用也非常重要。
四、结论
价值
- 降低成本:该混合模型可以在资源受限环境进行精准识别,有利于降低识别成本
- 跨领域应用:研究成果不仅限于疫情信息,还可能扩展到其他类型的社交媒体虚假信息识别
意义
本文的研究成果对于减少社交媒体上虚假疫情信息的传播具有重要价值,有助于增强公众对健康信息的正确理解,同时对信息疫情治理提供了有效的技术解决方案。此外,研究还为类似问题提供了方法论的参考,具有广泛的应用前景和社会影响。

















